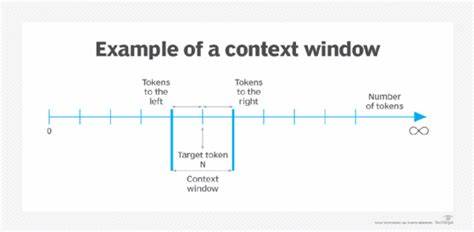
Los modelos Transformers han revolucionado el procesamiento del lenguaje natural (PLN) en los últimos años, permitiendo avances sorprendentes en tareas como traducción automática, generación de texto, respuesta automática y muchas otras aplicaciones. Uno de los conceptos clave detrás de la eficacia de los Transformers es la llamada "ventana de contexto" o "context window". Entender qué es esta ventana de contexto, por qué es tan importante y cómo es posible ampliarla es fundamental para aprovechar al máximo los modelos basados en Transformers tanto en investigación como en aplicaciones prácticas. La ventana de contexto se refiere al número máximo de tokens o unidades de texto que un modelo puede procesar de manera simultánea para comprender y generar respuestas coherentes. En términos simples, es la longitud del fragmento de texto que el modelo puede "ver" y analizar a la vez para tomar decisiones informadas.
Si pensamos en una conversación, por ejemplo, la ventana de contexto representa el límite del historial que el modelo puede considerar para mantener la coherencia en sus respuestas. La longitud de esta ventana es crucial porque determina la capacidad del modelo para manejar coherencia a largo plazo, referencias cruzadas dentro del texto y entender contextos amplios que van más allá de frases o párrafos aislados. Un límite pequeño puede hacer que el modelo pierda información importante o que las respuestas sean menos precisas cuando el contexto es extenso, mientras que una ventana de contexto más amplia mejora la comprensión, permitiendo que el modelo capte matices y relaciones complejas en fragmentos largos de texto. Los primeros modelos Transformers tenían ventanas de contexto relativamente pequeñas, con límites alrededor de 512 a 1024 tokens, debido a limitaciones computacionales y de memoria. Sin embargo, a medida que los avances en hardware y arquitectura se consolidaron, esta capacidad ha ido creciendo.
Modelos modernos como GPT-3 y posteriores cuentan con ventanas de contexto que pueden alcanzar hasta 2048 tokens y más, permitiendo analizar textos considerablemente largos sin perder coherencia. Para hacer más larga la ventana de contexto en un modelo Transformer, se han explorado varias estrategias tanto a nivel de arquitectura como de optimización computacional. Una de las técnicas consiste en modificar el mecanismo de atención, que es el núcleo de los Transformers. La atención tradicional calcula relaciones entre todos los tokens de la secuencia, lo que genera un costo computacional cuadrático conforme aumenta la longitud de la ventana. Este costo limita directamente la capacidad práctica para extender el contexto.
Por ello, se han desarrollado variantes de atención más eficientes, conocidas como "atención escasa" o "atención eficiente", que reducen la complejidad al limitar los tokens a los más relevantes o mediante agrupamientos inteligentes. Entre estas técnicas destacan los Transformers como Longformer, Reformer y BigBird, que permiten manejar secuencias de cientos de miles de tokens de forma más viable desde un punto de vista computacional. Otra aproximación para ampliar la ventana de contexto es el uso de mecanismos de memoria externa. Aquí, el modelo guarda representaciones resumidas de fragmentos anteriores y las incorpora en la generación continua de texto, logrando una especie de "memoria extendida" que se combina con la ventana de contexto nativa. Esta estrategia es útil para contextos muy largos, como libros o documentos extensos, donde sería imposible alimentar todo el texto de forma directa.
Desde una perspectiva práctica, al trabajar con modelos como GPT o similares, para aprovechar ventanas de contexto más largas es importante también preparar los datos de entrada adecuadamente, segmentando el texto de modo que se maximice el uso del contexto disponible. Esto incluye técnicas de preprocesamiento que mantienen la coherencia entre segmentos y el manejo de referencias cruzadas en textos extensos. Además, algunas implementaciones recientes ofrecen APIs o versiones de modelos específicamente optimizadas con ventanas de contexto extendidas, lo que facilita a desarrolladores y usuarios finales la incorporación de esta capacidad sin necesidad de modificar intensamente la infraestructura interna. No obstante, ampliar la ventana de contexto no está exento de desafíos. Aumentar la longitud de la secuencia demanda más memoria RAM y potencia de cálculo, lo que puede incrementar costos y tiempos de procesamiento.