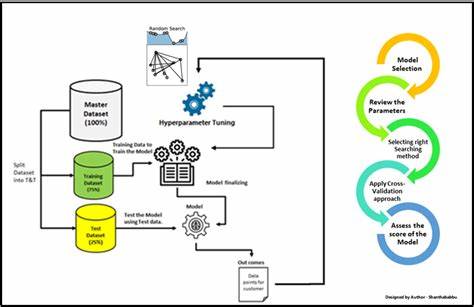
La optimización de hiperparámetros es un componente esencial dentro del desarrollo y entrenamiento de modelos de aprendizaje automático. Tradicionalmente, se asocia a la búsqueda intensiva de combinaciones adecuadas de parámetros que configuran un algoritmo, con el objetivo de maximizar su desempeño. Sin embargo, a medida que los modelos crecen en complejidad y las posibilidades de ajuste se multiplican, surge una nueva perspectiva que considera este proceso no solo como una simple búsqueda, sino como un desafío de programación y administración de recursos limitados. Al enfrentar un vasto espacio de hiperparámetros, la cantidad total de combinaciones posibles que se pueden probar se vuelve inmanejable. Esto se traduce en tiempos de entrenamiento muy prolongados y en una demanda de capacidad computacional que rápidamente excede los recursos disponibles.
En este sentido, la optimización ya no es solo tratar de encontrar el mejor conjunto de parámetros sino también decidir cómo distribuir de manera inteligente el tiempo y el poder computacional entre diferentes configuraciones. Pensar en la sintonización de hiperparámetros como un problema de programación de recursos implica reconocer que el entrenamiento de cada modelo es una tarea con una duración y costo específicos, y que el sistema debe gestionar estas ejecuciones como si fueran trabajos a programar en un entorno con capacidad limitada. La clave está en determinar cuáles modelos merece la pena entrenar, cuánto tiempo o recursos se deben asignar a cada uno, y cuándo es apropiado detener aquellos que parecen no ofrecer un beneficio suficiente. Este enfoque es especialmente crucial en escenarios donde el tiempo de cómputo es un recurso escaso y costoso. Por ejemplo, entrenar un modelo profundo con millones de parámetros sobre grandes conjuntos de datos puede durar horas o días por iteración.
Intentar muestrear exhaustivamente todas las posibles combinaciones de hiperparámetros se vuelve inviable. Por ello, las estrategias modernas de optimización implementan mecanismos para realizar una especie de “pre-selección” y asignar dinámicamente recursos de acuerdo con el desempeño inicial. Entre las técnicas más destacadas que ejemplifican esta gestión de recursos se encuentran ASHA (Asynchronous Successive Halving Algorithm), Hyperband y Population-Based Training (PBT). Estas metodologías no solo buscan explorar amplios espacios de hiperparámetros sino que lo hacen priorizando las configuraciones más prometedoras, deteniendo prematuramente aquellas que muestran malos resultados, y reasignando recursos hacia las mejores. ASHA, por ejemplo, comienza con un gran número de configuraciones entrenadas con una cantidad mínima de recursos.
De manera asincrónica, evalúa el desempeño parcial de estos modelos y elimina sistemáticamente a los que no cumplen con un umbral competitivo. De este modo se asegura que los recursos se concentren más rápidamente en las configuraciones que parecen ofrecer mayor potencial, sin esperar que todos los modelos completen su entrenamiento. Hyperband extiende esta idea al combinar múltiples rondas de Successive Halving con diferentes presupuestos iniciales. Así, permite cubrir desde configuraciones que reciben pocos recursos a otras con niveles más altos de tiempo de entrenamiento, estableciendo un balance efectivo entre exploración y explotación. Esto significa que se garantizan tanto oportunidades para descubrir nuevas combinaciones como para profundizar en las más prometedoras.
Population-Based Training adopta un enfoque evolutivo, manteniendo simultáneamente un conjunto de modelos con hiperparámetros diversos que se entrenan paralelamente. A intervalos regulares, aquellos con mejor desempeño “sobreviven” y transmiten o mutan sus hiperparámetros, mientras que los peores son reemplazados o ajustados. Esta dinámica conlleva una optimización continua que aprovecha la exploración y la explotación simultáneamente. Estas técnicas comparten una perspectiva común: adoptar principios similares a los de un sistema de programación de tareas. Cada entrenamiento es tratado como un trabajo que consume recursos limitados.
Decidir cuándo continuar, cuándo detener y cuándo priorizar ciertas tareas es análogo a la gestión que se realiza en entornos con alta carga de trabajos y capacidades computacionales compartidas. Además de la eficiencia computacional, este enfoque tiene un impacto clave en la velocidad para encontrar buenos modelos. Al limitar el tiempo invertido en configuraciones poco prometedoras, se gana rapidez para concentrar esfuerzos en aquellas configuraciones que realmente mejoran el resultado. Más allá de los métodos descritos, las tendencias futuras apuntan hacia una integración aún mayor entre la optimización de hiperparámetros y técnicas de meta-aprendizaje y evolución adaptativa. El meta-aprendizaje busca aprovechar la experiencia previa en optimizaciones anteriores para acelerar la búsqueda de hiperparámetros en nuevas tareas, aprendiendo patrones y recomendaciones óptimas.